
What is speech-to-text?
Speech-to-text is an experimental new service provided by Virbela. It transcribes speech, renders a caption on the screen, and provides translation services.
When enabling speech-to-text (STT) please be mindful of what rooms require speech translation and accessibility. Virbela currently offers STT as a complimentary, experimental feature, and incurs costs as our customers use this service. As a result, we may, in the future, need to cap the usage of this feature or charge our customers. We will provide advance notice if this were to happen.
Do customers need to update their firewall rules?
Customers need to add the following to their allow list to use speech-to-text.
| Description | Endpoint | Reason |
|---|---|---|
| Azure Transcription Service |
https://*.api.cognitive.microsoft.com https://*.stt.speech.microsoft.com both are TCP Port 443 |
If this is blocked for a user, their speech will not be transcribed. |
| Multiplexer |
https://textdelivery.virbela.com port: 443 |
If this is blocked for a user, transcriptions of other users’ speech will not be delivered. |
Speech-to-Text works in all regions. However, currently, Virbela only offers one endpoint based in the United States, and this is just for data pass-through - no additional data is stored in the United States.
Virbela will add additional endpoints soon. If customers add the wildcard at the start of the Azure Transcription Service standpoint, we can add these endpoints without requiring customers to update their firewall rules.
The Virbela campus will work fine if these firewall rules are not added, and these rules only impact the speech-to-text functionality.
Are the minimum requirements for Speech-to-Text different from Virbela’s minimum system requirements?
Yes, Speech-to-Text requires Windows 10 or higher or macOS version 10.14 or later.

How do I enable Speech-to-Text for my campus?
To enable speech-to-text, campus owners must first contact their account manager. They will work with the Virbela IT team to allow speech-to-text for the campus.
Once the IT team has completed this step, campus owners must enable the global speech-to-text setting in the Virbela dashboard world screen.
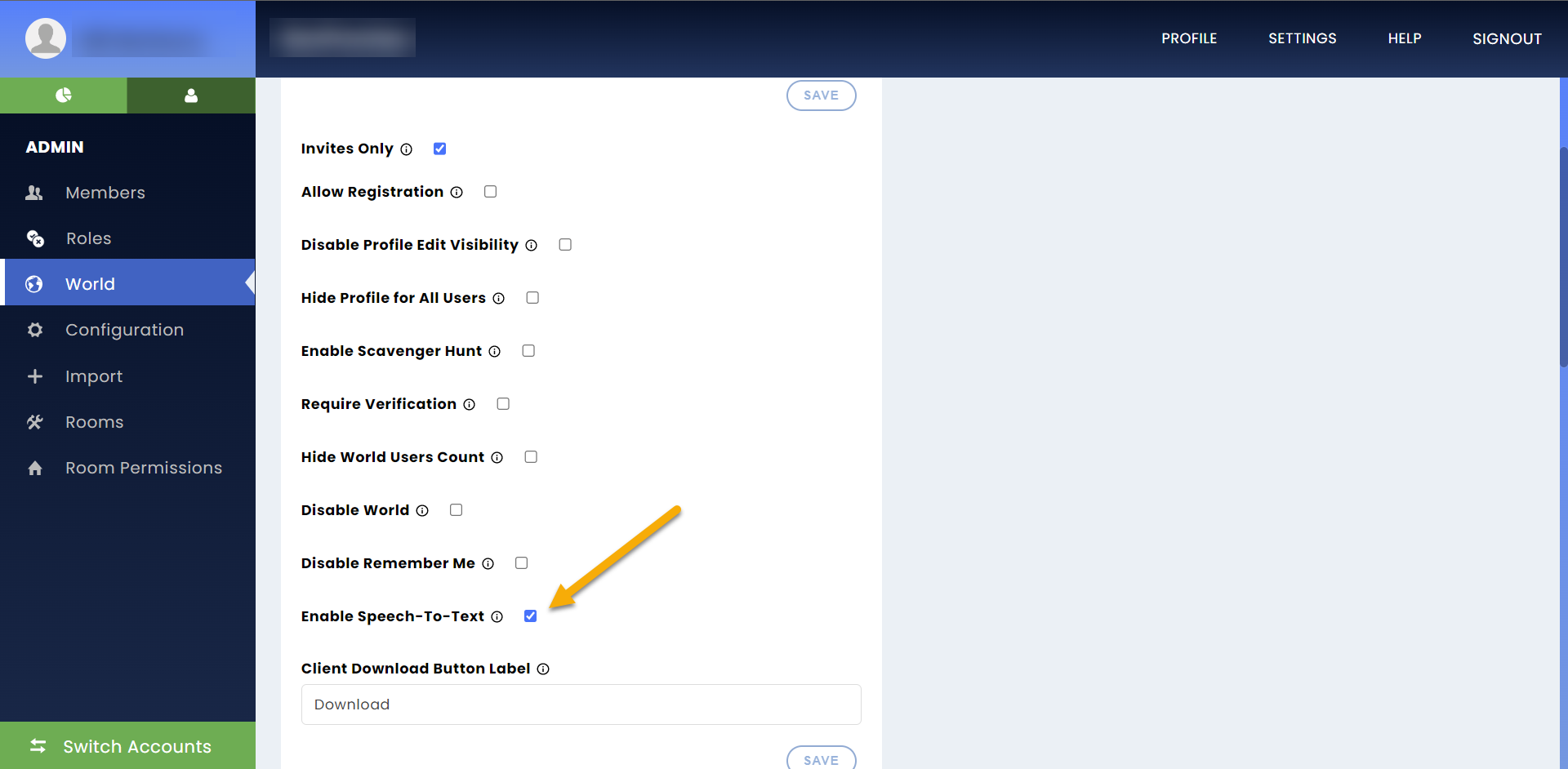
If you enable speech-to-text for your campus and specific rooms and disable speech-to-text for your campus, all rooms will stop transcribing. However, Virbela remembers the room setting, so when you re-enable the global setting, all rooms that previously had STT enabled will start transcribing.
All rooms are enabled by default. To disable individual rooms, enter the campus and go to the room with speech-to-text allowed. Click Room Settings under the gear menu, then click the checkbox next to Enable Speech-to-Text.
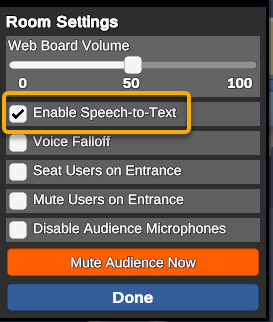
The above room settings are for the auditorium scene. Other scenes may show different options than what appears above. However, all scenes will have the Enable Speech-to-Text option.
How will users know if a room has speech-to-text disabled?
If speech-to-text is disabled in a particular room, users will see this prompt after entering:

How can users enable the transcription of speech-to-text?
Before users can enable the in-world transcription, campus administrators must enable speech-to-text in the Virbela dashboard.
Users can enable transcription in the preferences menu found under the gear menu. Users need to click the checkbox next to Transcribe speech into the text.
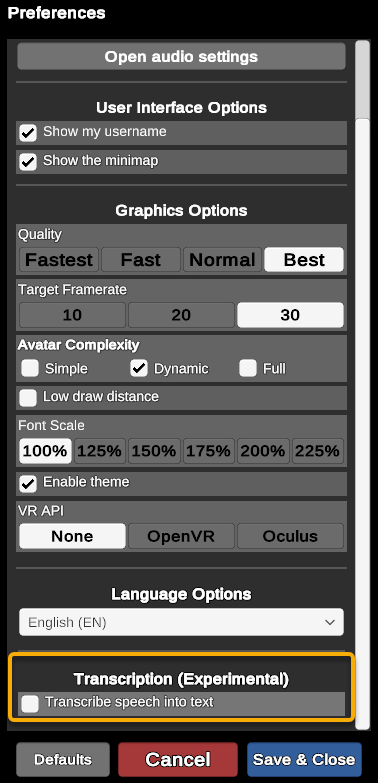
A pop-up will appear the first time a user enables speech-to-text. Users must accept these terms to allow speech-to-text transcriptions, and Virbela tracks which users have accepted these terms.
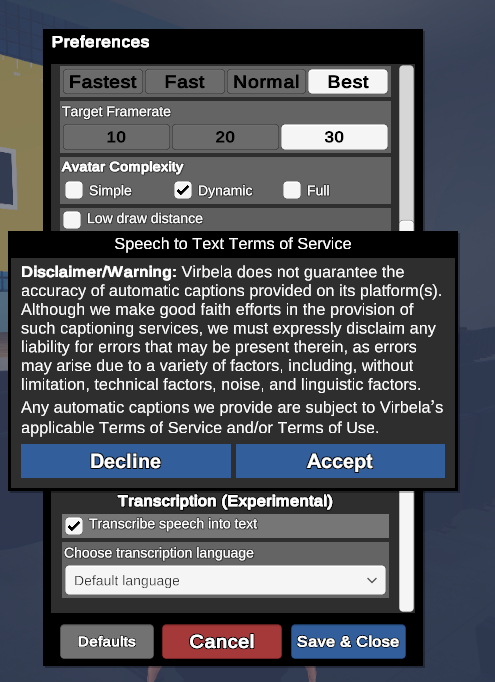
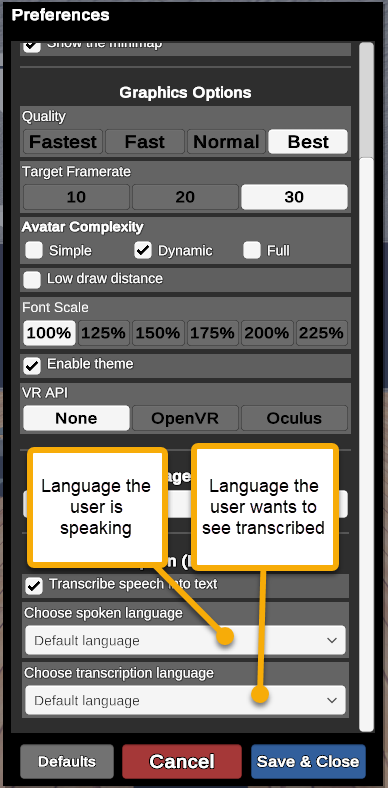
After users enable speech-to-text, they can determine whether they want to transcribe the speech into their default language (whatever they have set as their language in Virbela) or if they want to translate the speech into another language. The user must select the language in the dropdown.
For correct transcription, speech-to-text requires a user to specify the input language (i.e., the speaker's language). In other words, if the user has selected English as the default language, but the speaker is speaking in Spanish, the transcription will not transcribe correctly.
Even when a user enables speech-to-text, the transcription will only appear in rooms allowed in the room settings tool by campus administrators.
How does the translation service work?
The translation service considers the speaker's language preference and the user's output preference.
In this example, English is chosen. If the user speaks English, the speech-to-text service will accurately transcribe and translate their speech. However, if they speak another language other than English, it will not transcribe and translate correctly.
Users must indicate their language using the Choose spoken language field. Selecting Default language will allow the system to use the language chosen under Language Options. Users also need to indicate the language they want to appear in the transcription.
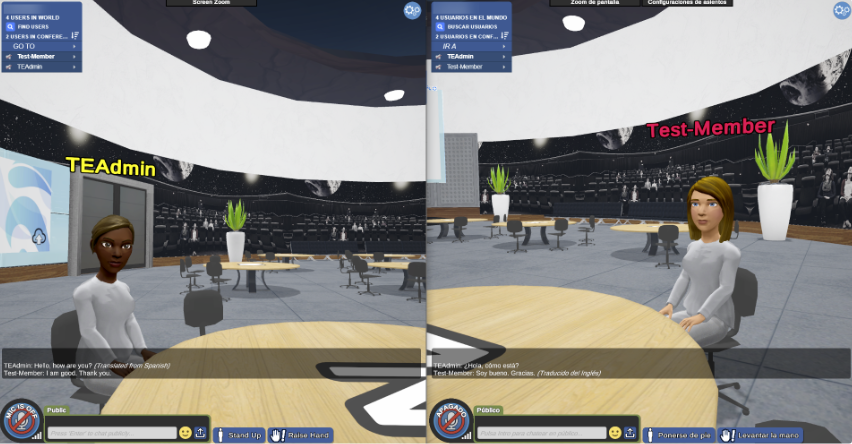
Below is an example of two users talking to each other in different languages. The user on the left has chosen English as both their system preferences and transcription language. The user on the right has chosen Spanish as both their system preferences and transcription language.
The user on the left speaks English, and the user on the right speaks Spanish. However, both users see the transcription in their native language.
How does speech-to-text appear to the user?
When the user enables the feature, speech-to-text will appear just above the chat window.

As one or more users continue to speak, more text will appear in the window:

The most recent chat will appear at the bottom when users continue speaking. However, users can scroll up to see the history.

The chat menu will then return to the latest thread.

Currently, history lasts for twenty seconds.
How sensitive is the microphone? What voice will it capture?
The speech-to-text service will transcribe everything within the voice falloff range. In other words, if a user is located on the main campus, the transcription will transcribe the voice of other users around the user. However, it will not transcribe the voice of users on the other side of the campus.
Speech-to-text will not transcribe users who are sitting in a different private volume. However, if a user enters a private volume, there is a chance that speech-to-text will still transcribe the discussion that occurred a few seconds before a user arrived. If a sensitive conversation happens, we encourage users to lock their doors or disable speech-to-text in the room.
Does Virbela keep transcription history? Am I able to download the transcription?
Virbela does not maintain a transcription history; once the transcription disappears from the screen, it is lost forever.
No, users cannot download or copy the transcription at this time.
What languages are supported?
The speech-to-text service can translate into any language already supported by Virbela.
Will speech-to-text also translate chat messages?
No, it will not translate chat messages.
Can users opt out of having their voice transcribed?
No, not at this time.
Does speech-to-text work when multiple users speak at once?
Yes, speech-to-text does work when multiple users speak at once. However, the transcription is hard to follow if users are talking over each other and interrupting.
Will speech-to-text work with live streams?
Speech-to-text will transcribe every user who is speaking. However, it will not transcribe videos or live streams.
Will it respond to user-selected voice sensitivity settings?
Yes, it will.